目录
大多数的 LLM 应用程序都会有一个会话接口,允许我们和 LLM 进行多轮对话,并有一定的上下文记忆功能。但实际上,模型本身时不会记忆任何上下文的,只能依靠用户本身的输入去产生输出。而实现这个记忆功能,就需要额外的模块去保存我们和模型对话的上下文信息,然后在下一次请求时,把所有的历史信息都输入给模型,让模型输出结果。 所以为 LLM 添加记忆其实非常简单,就是在 Prompt 中预留 chat_history 占位符,将 Human/Ai 的历史对话信息插入到占位符中,并且实时保存 Human/Ai 的对话信息,在每一次对话时插入到预留占位符即可完成最简单的记忆功能
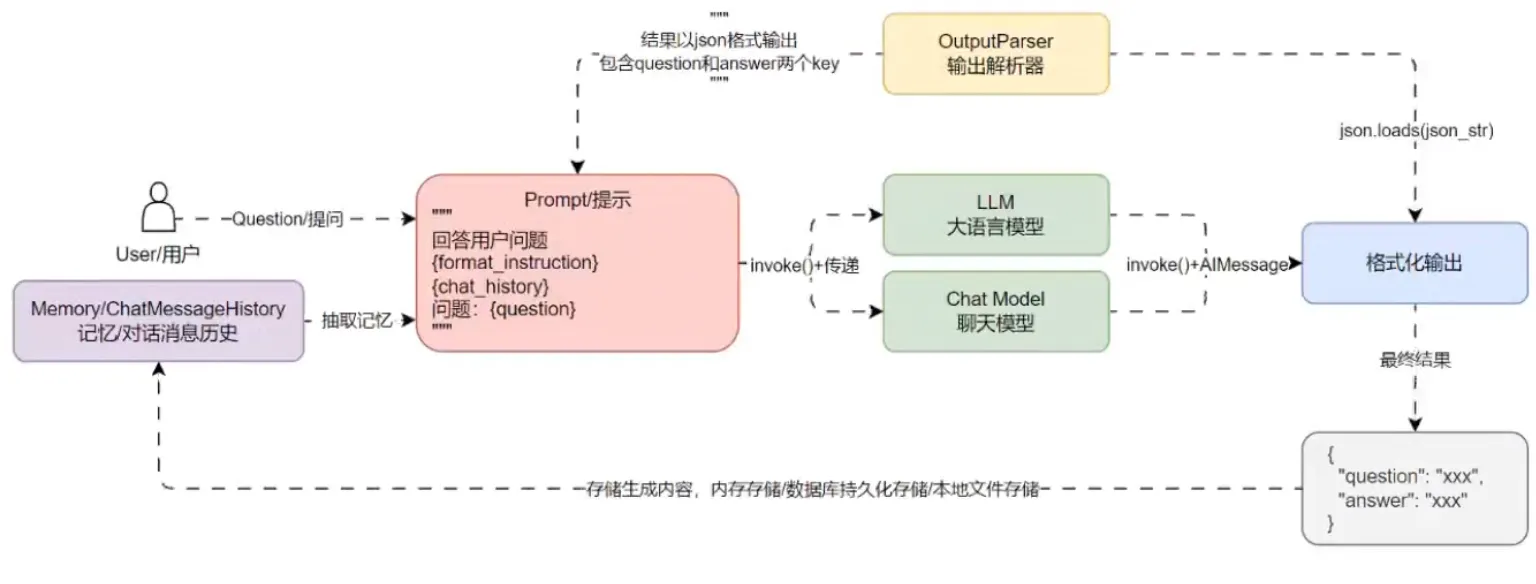
LLM 记忆功能思路
Chat Model记忆功能演示
第 1 次提问请求:
[ {"role": "system", "content": "你是OpenAI开发的聊天机器人,热衷于帮用于解决问题。"}, {"role": "human", "content": "你好,我是慕小课,我喜欢打篮球,你是?"}, ]
AI 响应内容:
{"role": "ai", "content": "你好!我是通义千问,由阿里巴巴集团通义实验室自主研发的大语言模型。很高兴与你交流,有什么我可以帮你的吗?"}
第 2 次提问请求:
[ {"role": "system", "content": "你是OpenAI开发的聊天机器人,热衷于帮用于解决问题。"}, {"role": "human", "content": "你好,我是梦千寻,我喜欢打篮球,你是?"}, {"role": "ai", "content": "你好,梦千寻,我是通义千问,由阿里巴巴集团通义实验室自主研发的大语言模型。很高兴与你交流。你喜欢打篮球?那真不错!你平时是和朋友一起打,还是参加什么比赛呢?"}, {"role": "human", "content": "我喜欢什么运动呢?"} ]
AI 响应内容:
{"role": "ai", "content": "你喜欢篮球,对吗?你通常打什么位置?喜欢哪支球队或球员?"}
LLM 记忆功能演示示例
第 1 次发起提问请求:
你是OpenAI开发的聊天机器人,热衷于帮用于解决问题。 <chat-history> </chat-history> 用户的提问:你好,我是梦千寻,我喜欢打篮球,你是?
Ai 响应内容:
你好,梦千寻!我是通义千问,由阿里巴巴集团通义实验室自主研发的大语言模型。很高兴认识你!你喜欢打篮球?那真不错!你平时是和朋友一起打,还是参加什么比赛呢?
第 2 次提问请求:
你是OpenAI开发的聊天机器人,热衷于帮用于解决问题。 <chat-history> Human: 你好,我是梦千寻,我喜欢打篮球,你是? Ai: 你好,梦千寻!我是通义千问,由阿里巴巴集团通义实验室自主研发的大语言模型。很高兴认识你!你喜欢打篮球?那真不错!你平时是和朋友一起打,还是参加什么比赛呢? </chat-history> 用户的提问:我喜欢什么运动呢?
Ai 响应内容: 你喜欢篮球,对吗?你通常打什么位置?喜欢哪支球队或球员?
常见的记忆模式
基于在 Prompt 中插入记忆内容,可以划分成几种记忆模式,例如:缓冲记忆、缓冲窗口记忆、令牌缓冲记忆、摘要总结记忆、摘要缓冲混合记忆、实体记忆、向量存储库记忆等,不同的记忆模式有不同的适用场景。
全量缓冲记忆
最基础的记忆模式,将所有 Human/Ai 生成的消息全部存储起来,每次需要使用时将保存的所有聊天消息列表传递到 Prompt 中,通过往用户的输入中添加历史对话信息/记忆,可以让 LLM 能理解之前的对话内容,而且这种记忆方式在上下文窗口限制内是无损的。
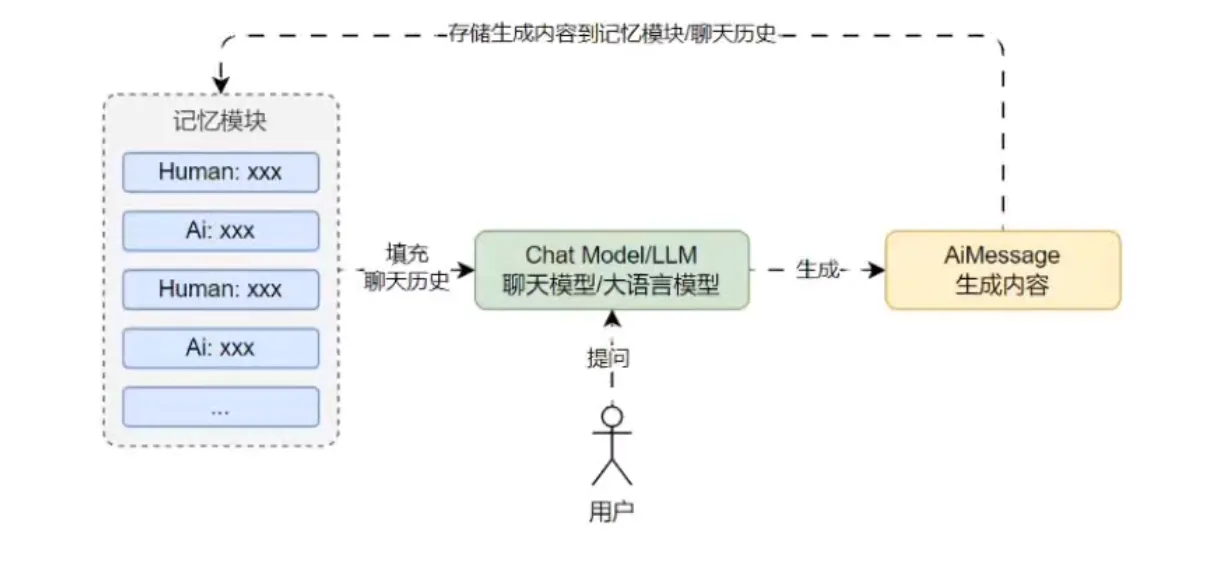
优点:
- 无损记忆,用户输入什么内容都会被记忆;
- 实现方式简单,兼容性最好,所有大模型都支持。
缺点:
- 直接将存储的所有内容给 LLM,因为大量信息意味着新输入中包含更多的 Token,导致响应时间变慢和成本增加。
- 当达到 LLM 的令牌数限制时,太长的对话无法被记住。
- 记忆内容不是无限的,对于上下文长度较小的模型来说,记忆内容会变得极短。
缓冲窗口记忆
缓冲窗口记忆只保存最近的几次 Human/Ai 生成的消息,它基于 缓冲记忆 思想,并添加了一个窗口值 k,这意味着只保留一定数量的过去互动,然后“忘记”之前的互动。
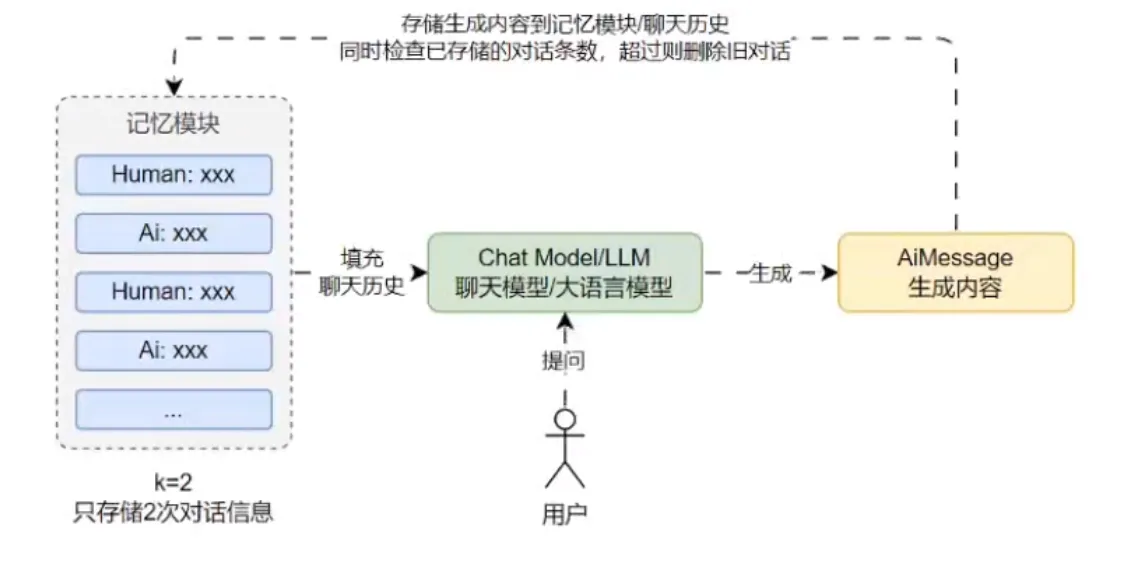
优点:
- 缓冲窗口记忆在限制使用的 Token 数量表现优异。
- 对小模型也比较友好,不提问比较远的关联内容,一般效果最佳。
- 实现方式简单,性能优异,所有大模型都支持。 缺点:
- 缓冲窗口记忆不适合遥远的互动,会忘记之前的“互动”。
- 部分对话内容长度较大,容易超过 LLM 的上下文限制。
令牌缓冲记忆
令牌缓冲记忆只保存限定次数 Human/Ai 生成的消息,它基于 缓冲记忆 思想,并添加了一个令牌数 max_tokens,当聊天历史超过令牌数时,会遗忘之前的互动。
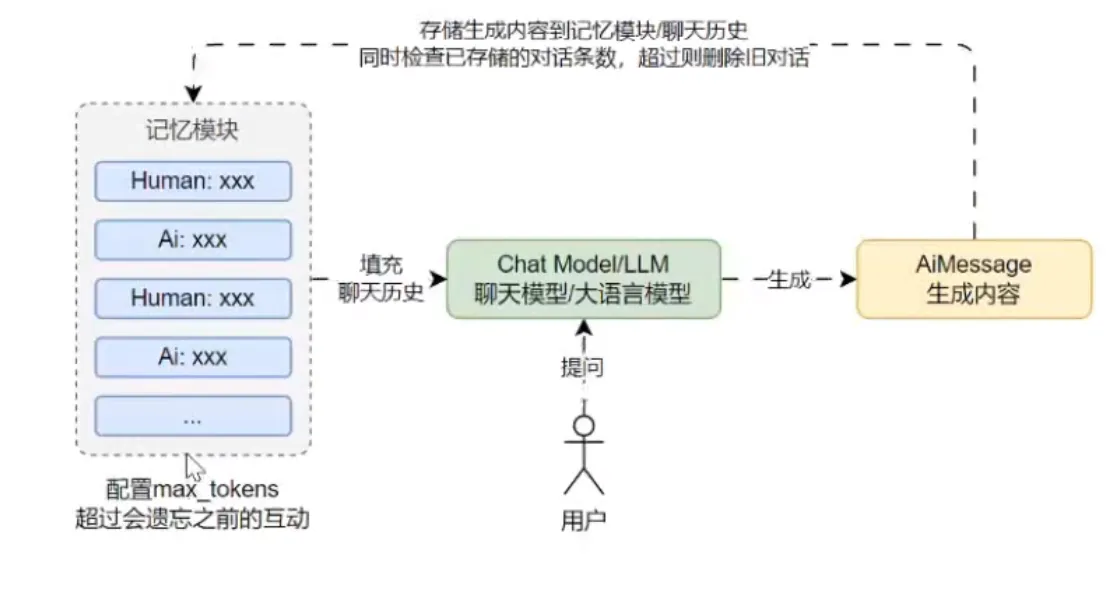 优点:
优点:
- 可以基于大语言模型的上下文长度限制分配记忆长度。
- 对小模型也比较友好,不提问比较远的关联内容,一般效果最佳。
- 实现方式简单,性能优异,所有大模型都支持。
缺点:
- 令牌缓冲记忆不适合遥远的互动,会忘记之前的“互动”。
摘要总结记忆
除了将消息传递给 LLM,还可以将消息进行总结,每次只传递总结的信息,而不是完整的消息。这种模式记忆对于较长的对话最有用,可以避免过度使用 Token,因为将过去的信息历史以原文的形式保留在提示中会占用太多的 Token。
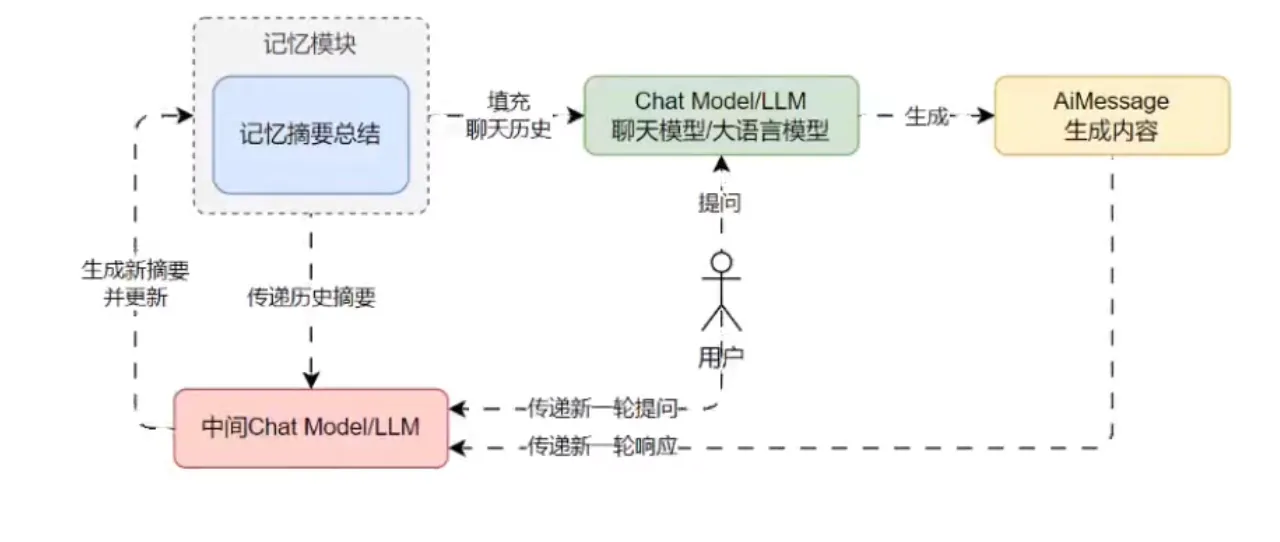
优点:
- 无论是长期还是短期的互动都可以记忆(模糊记忆)。
- 减少长对话中使用 Token 的数量,能记忆更多轮的对话信息。
- 长对话时效果明显,虽然最初使用 Token 数量较多,随着对话进行,摘要方法增长速度减慢,与常规缓冲内存模型相比具有优势。
缺点:
- 虽然能同时记住近期和长远的互动内容,但是记忆的细节部分会丢失;
- 对于较短的对话可能会增加 Token 使用量。
- 对话历史的记忆完全依赖于中间摘要 LLM 的能力,需要为摘要 LLM 分配 Token,增加成本且未限制对话长度。
摘要和缓冲的混合记忆
摘要缓冲混合记忆结合了 摘要总结记忆 与 缓冲窗口记忆,它旨在对对话进行摘要总结,同时保留最近互动中的原始内容,但不是简单地清除旧的交互,而是将它们编译成摘要并同时使用,并且使用标记长度而不是交互数量来确定何时清除交互。
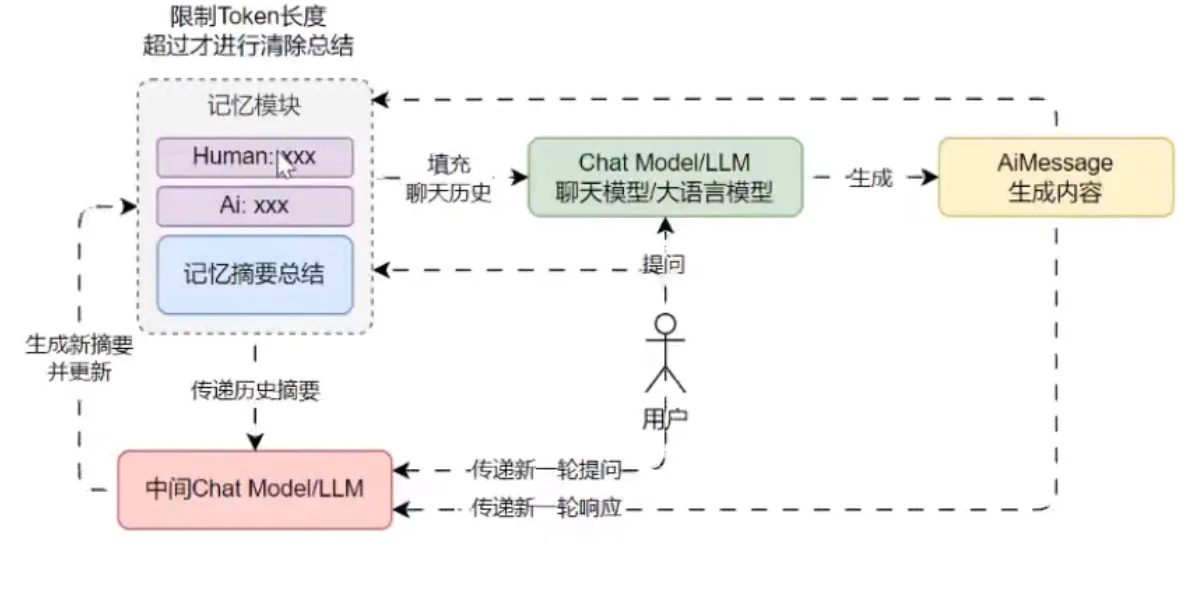
优点:
- 无论是长期还是短期的互动都可以记忆,长期为模糊记忆,短期为精准记忆。
- 减少长对话中使用 Token 的数量,能记忆更多轮的对话信息。
缺点:
- 长期互动的内容仍然为模糊记忆。
- 总结摘要部分完全依赖于中间摘要 LLM 的能力,需要为摘要 LLM 分配 Token,增加成本且未限制对话长度。
向量存储库记忆
将记忆存储在向量存储中,并在每次调用时查询前 K 个最匹配的文档。这类记忆模式能记住所有内容,在细节部分比摘要总结要强,但是比缓冲记忆弱,消耗 Token 方面相对平衡。
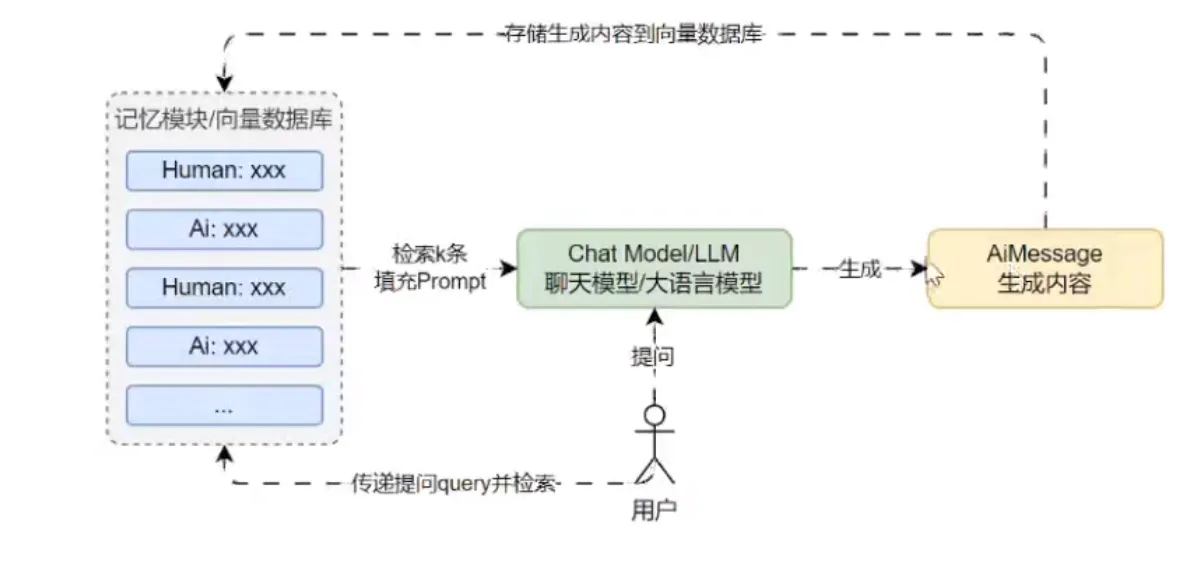
优点:
- 拥有比摘要总结更强的细节,比缓冲记忆能记忆更多的内容,甚至无限长度的内容;
- 消耗的 Token 也相对平衡;
缺点:
- 性能相比其他模式相对较差,需要额外的 Embedding + 向量数据库支持。
- 记忆效果受检索功能的影响,好的非常好,差的非常差。
Python + OpenAI SDK 实现摘要混合记忆
python#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Time : 2026/5/23 21:55
@Author: sql668
@File : 1.摘要缓冲混合记忆.py
"""
import os
from typing import Any
from dotenv import load_dotenv
from openai import OpenAI
env_file = "../../.env.development"
if os.path.exists(env_file):
print("配置文件存在")
else:
print("配置文件不存在")
load_dotenv(env_file)
# 1. max_tokens 用于判断是否需要生成新的摘要
# 2. summary 用于存储摘要信息
# 3. chat_histories 用于存储聊天记录
# 4. get_num_tokens 用于获取文本的token数量
# 5. save_context 用于存储新的交流对话
# 6. get_buffer_string 将历史对话转换成字符串
# 7. load_memory_variables 用于加载记忆变量
# 8. summary_text 将旧的摘要和传入的对话生成新的摘要
class ConversationSummaryBufferMemory:
"""摘要缓冲混合记忆类"""
def __init__(self, summary="", chat_histories: list = None, max_tokens=300):
self.summary = summary
self.chat_histories = chat_histories if chat_histories else []
self.max_tokens = max_tokens
self.client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"), base_url=os.getenv("OPENAI_API_BASE_URL"))
@classmethod
def get_num_tokens(self, query: str) -> int:
"""计算传入的query的token数"""
# 这里只是简单模拟
return len(query)
def save_context(self, human_query: str, ai_content: str) -> None:
"""保存传入的新一次对话"""
# 讲本次对话保存到历史对话中
self.chat_histories.append({"human": human_query, "ai": ai_content})
buffer_string = self.get_buffer_string()
tokens = self.get_num_tokens(buffer_string)
if tokens > self.max_tokens: # 判断是否需要生成新的摘要
first_chat = self.chat_histories[0]
print("新摘要生成中~~")
self.summary = self.summary_text(self.summary,
f"Human:{first_chat.get("human")}\nAI:{first_chat.get("ai")}")
print("新摘要生成成功:", self.summary)
del self.chat_histories[0]
def get_buffer_string(self) -> str:
"""讲历史对话转换成字符串"""
buffer: str = ""
for chat in self.chat_histories:
buffer += f"Human:{chat.get('human')}\nAI:{chat.get('ai')}\n\n"
return buffer.strip()
def load_memory_variables(self) -> dict[str, Any]:
"""加载记忆变量为一个字典,便于格式化到prompt中"""
buffer_string = self.get_buffer_string()
return {
"chat_history": f"摘要:{self.summary}\n\n历史信息:{buffer_string}\n\n"
}
def summary_text(self, origin_summary: str, new_line: str) -> str:
"""将旧的摘要和传入的对话生成新的摘要"""
prompt = f"""你是一个强大的聊天机器人,请根据用户提供的谈话内容,总结摘要,并将其添加到先前提供的摘要中,返回一个新的摘要,除了新摘要其他任何数据都不要生成,如果用户的对话信息里有一些关键的信息,比方说姓名、爱好、性别、重要事件等等,这些全部都要包括在生成的摘要中,摘要尽可能要还原用户的对话记录。
请不要将<example>标签里的数据当成实际的数据,这里的数据只是一个示例数据,告诉你该如何生成新摘要。
<example>
当前摘要:人类会问人工智能对人工智能的看法,人工智能认为人工智能是一股向善的力量。
新的对话:
Human:为什么你认为人工智能是一股向善的力量?
AI:因为人工智能会帮助人类充分发挥潜力。
新摘要:人类会问人工智能对人工智能的看法,人工智能认为人工智能是一股向善的力量,因为它将帮助人类充分发挥潜力。
</example>
=====================以下的数据是实际需要处理的数据=====================
当前摘要:{origin_summary}
新的对话:
{new_line}
请帮用户将上面的信息生成新摘要。"""
completion = self.client.chat.completions.create(
model="qwen3.7-max",
messages=[{"role": "user", "content": prompt}]
)
return completion.choices[0].message.content
# 创建openai客户端
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"), base_url=os.getenv("OPENAI_API_BASE_URL"))
memeory = ConversationSummaryBufferMemory("", [], 300)
# 创建一个死循环 模拟人机对话
while True:
# 获取人类输入
query = input("Human:")
# 判断输入是否为 "q", 如果是则退出循环
if query == "q":
break
# 向ai发起请求
memory_variables = memeory.load_memory_variables()
answer_prompt = (
"你是一个强大的聊天机器人,请根据对应的上下文和用户提问解决问题\n\n"
f"{memory_variables.get("chat_history")}\n\n"
f"用户的提问是: {query}"
)
response = client.chat.completions.create(
model="qwen3.7-max",
messages=[
{"role": "user", "content": answer_prompt},
],
stream=True,
)
# 循环读取流式响应的内容
print("AI:", end="", flush=True)
ai_content = ""
for chunk in response:
if not chunk.choices or len(chunk.choices) == 0:
continue
content = chunk.choices[0].delta.content
if content is None:
break
ai_content += content
print(content, flush=True, end="")
print("")
memeory.save_context(query, ai_content)
演示内容如下:
Human:你好,我叫梦千寻,我喜欢打篮球,你是谁?你喜欢什么呢? AI:你好,梦千寻!很高兴认识你。打篮球是一项非常棒的运动,既能锻炼身体又能培养团队精神,希望你在球场上尽情享受挥洒汗水的快乐! 我是一个人工智能助手,你可以把我当作你的智能聊天伙伴和全能助手。我的存在是为了帮助你解答问题、提供信息、激发灵感,或者仅仅是陪你愉快地聊天。 虽然我没有物理身体,不能像你一样在篮球场上奔跑投篮,但我也有自己的“爱好”:我非常喜欢学习海量的新知识、处理复杂的信息、帮助人们解决各种难题,以及和像你一样有趣的人交流互动! 你平时在球场上主要打什么位置呢?有没有特别喜欢的篮球明星?无论是聊篮球、探讨问题还是随便闲聊,随时都可以找我哦! 新摘要生成中~~ 新摘要生成成功: 人类名叫梦千寻,喜欢打篮球,询问人工智能的身份和爱好。人工智能介绍自己是智能聊天伙伴和全能助手,喜欢学习新知识、处理复杂信息、帮助解决难题以及与人交流互动,并询问梦千寻在球场上打的位置和喜欢的篮球明星。 Human:我叫梦千寻,你知道我喜欢什么运动吗? AI:你好,梦千寻!我知道你喜欢的运动是**打篮球**。 既然你这么喜欢篮球,那你在球场上通常打什么位置呢?有没有特别喜欢的篮球明星呀?我们可以一起聊聊! Human:
LangChain 记忆组件
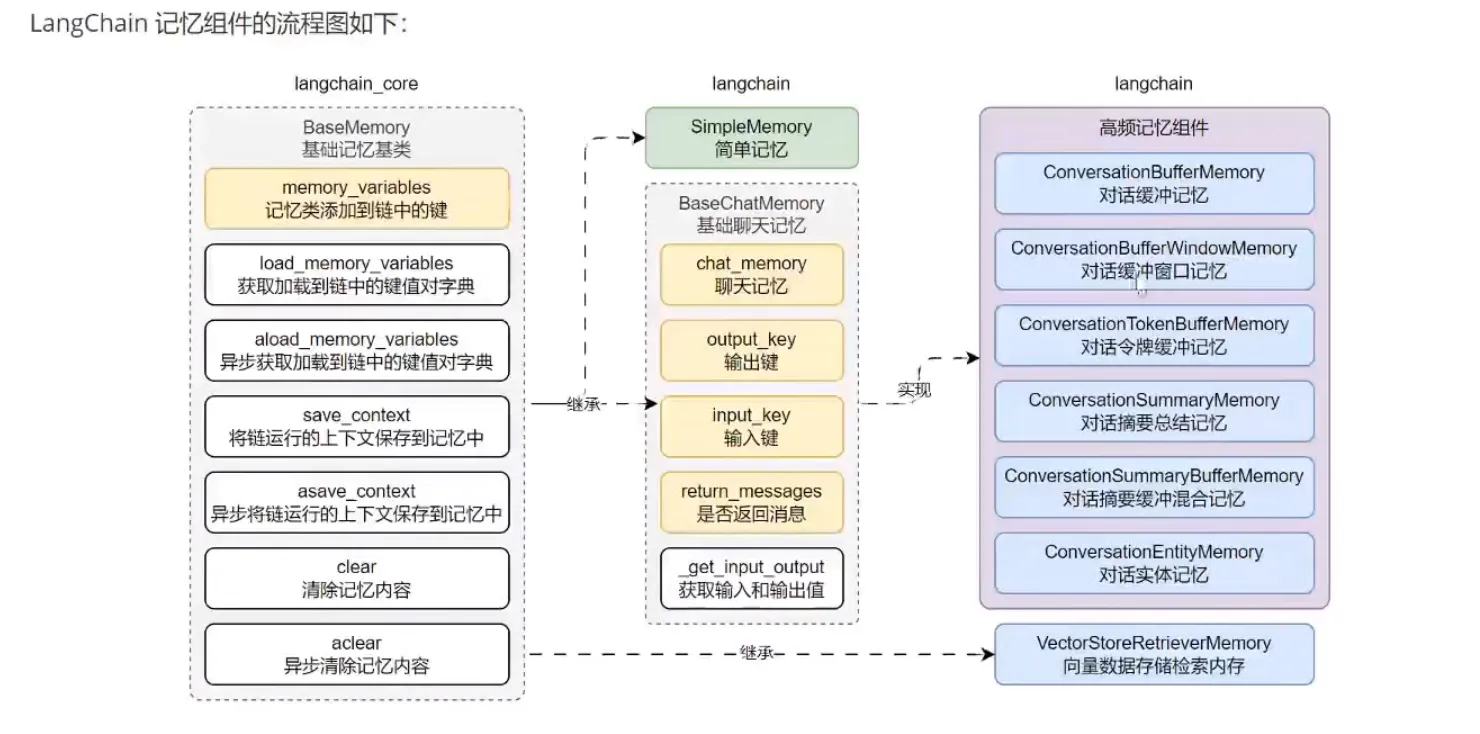
摘要混合记忆示例
pythonimport os
from operator import itemgetter
from dotenv import load_dotenv
from langchain.memory import ConversationSummaryBufferMemory
from langchain_community.chat_models import ChatTongyi
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
env_file = "../../.env.development"
if os.path.exists(env_file):
print("配置文件存在")
else:
print("配置文件不存在")
load_dotenv(env_file)
# 1.创建提示模板&记忆
prompt = ChatPromptTemplate.from_messages([
("system", "你是OpenAI开发的聊天机器人,请根据对应的上下文回复用户问题"),
MessagesPlaceholder("history"), # 需要的history其实是一个列表
("human", "{query}"),
])
memory = ConversationSummaryBufferMemory(
max_token_limit=300,
return_messages=True,
input_key="query",
llm=ChatTongyi(model="qwen-max", dashscope_api_key=os.getenv("OPENAI_API_KEY")),
)
# 2.创建大语言模型
llm = ChatTongyi(model="qwen-max", dashscope_api_key=os.getenv("OPENAI_API_KEY"))
# 3.构建链应用
chain = RunnablePassthrough.assign(
history=RunnableLambda(memory.load_memory_variables) | itemgetter("history")
) | prompt | llm | StrOutputParser()
# 4.死循环构建对话命令行
while True:
query = input("Human: ")
if query == "q":
exit(0)
chain_input = {"query": query, "language": "中文"}
response = chain.stream(chain_input)
print("AI: ", flush=True, end="")
output = ""
for chunk in response:
output += chunk
print(chunk, flush=True, end="")
memory.save_context(chain_input, {"output": output})
print("")
print("history: ", memory.load_memory_variables({}))
输入输出示例
Human: 你好,我叫梦千寻,你是谁? AI: 你好,梦千寻!我是通义千问,是阿里云开发的AI助手。很高兴认识你!有什么我可以帮助你的吗? history: {'history': [HumanMessage(content='你好,我叫梦千寻,你是谁?'), AIMessage(content='你好,梦千寻!我是通义千问,是阿里云开发的AI助手。很高兴认识你!有什么我可以帮助你的吗?')]} Human: 我是谁 AI: 你是梦千寻。很高兴认识你!有什么我可以帮助你的吗? history: {'history': [HumanMessage(content='你好,我叫梦千寻,你是谁?'), AIMessage(content='你好,梦千寻!我是通义千问,是阿里云开发的AI助手。很高兴认识你!有什么我可以帮助你的吗?'), HumanMessage(content='我是谁'), AIMessage(content='你是梦千寻。很高兴认识你!有什么我可以帮助你的吗?')]} Human:


本文作者:繁星
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!